Information in this article applies to Safetica 10 or older.
In Safetica 10, we made a great technological leap and replaced our existing sensitive content detection with a more accurate and powerful one.
In this article, you will learn:
- How does the new sensitive content detection work?
- Where to configure the new sensitive content detection?
- For what file types can you launch sensitive content detection?
- How to exclude certain content from analysis?
- What does the admin see in logs?
How does the new sensitive content detection work?
Safetica now runs with a completely new content core and text parsers that support more file types than the previous technology.
You can now gain a more granular control of what specific file types (such as .docx and .xmlx) are analyzed for sensitive content in your company. This way, you unburden your environment, because all other files are not analyzed. At the same time, results are more accurate, since they only come from the files types specified.
Where to configure the new sensitive content detection?
As before, you can configure content detection in Safetica Management Console in Protection > Data categories. Just select a sensitive content data category in the list on the left or create a new one, and click the Configure data category button.
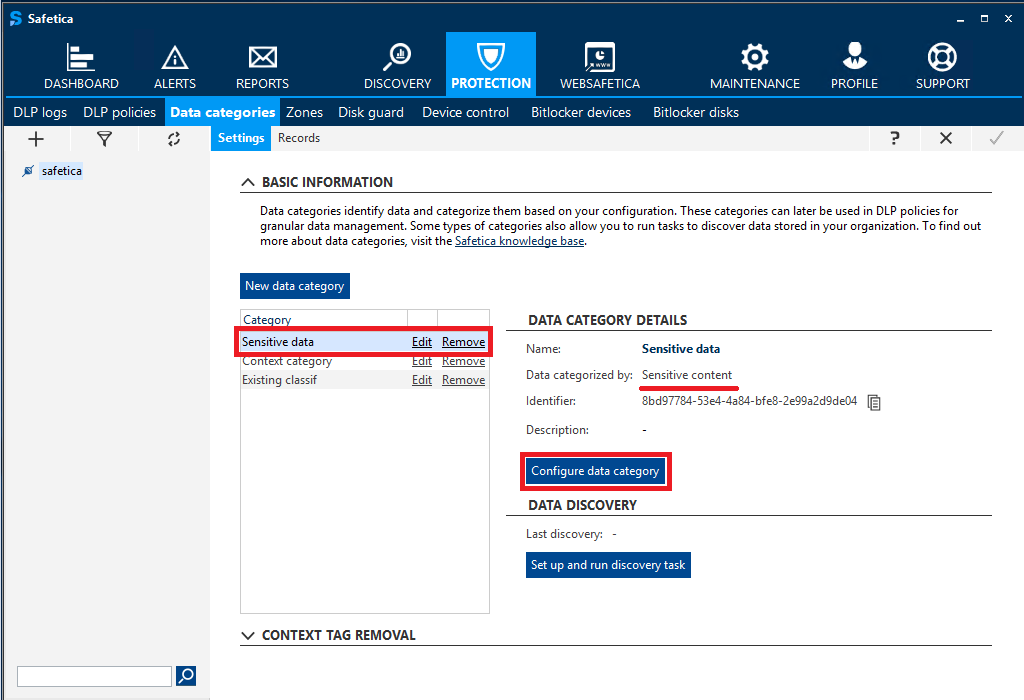
In the next step, you will see new options available under the detection rule configuration: Optical character recognition and Extensions. The sliders are independent of each other.
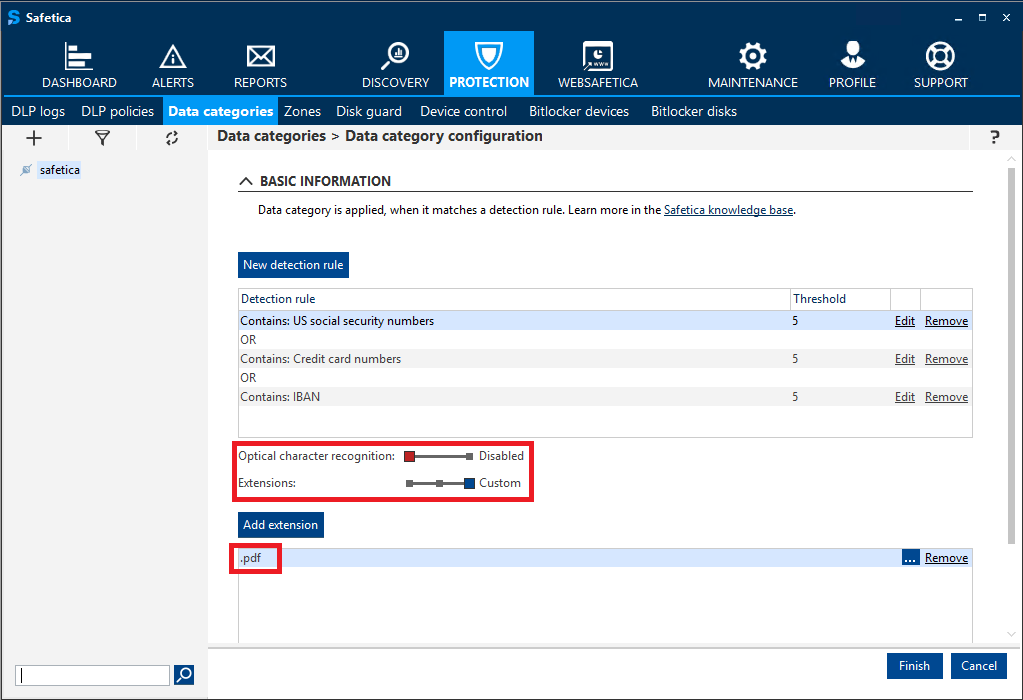
For what file types can you launch sensitive content detection?
With the Extensions slider, you can specify what types of files need to be analyzed for sensitive info defined by the detection rule above.
The slider offers the following options:
If you have several data categories set up with different extensions, Safetica will inspect all the file types.
How to exclude certain content from analysis?
Safetica 10 can skip content analysis for some files:
- You need to create a general "allow" policy.
- The exclusion will only work for the following policy rules:
- Cloud drives
- Upload to file share
- Upload to web mail
- Upload
- Instant messaging
- External devices
- Network file share
- Remote transfer
- The policy must be placed above all sensitive content policies in the list.
The content analysis exclusion also applies to Safetica Zones.
What does the admin see in logs?
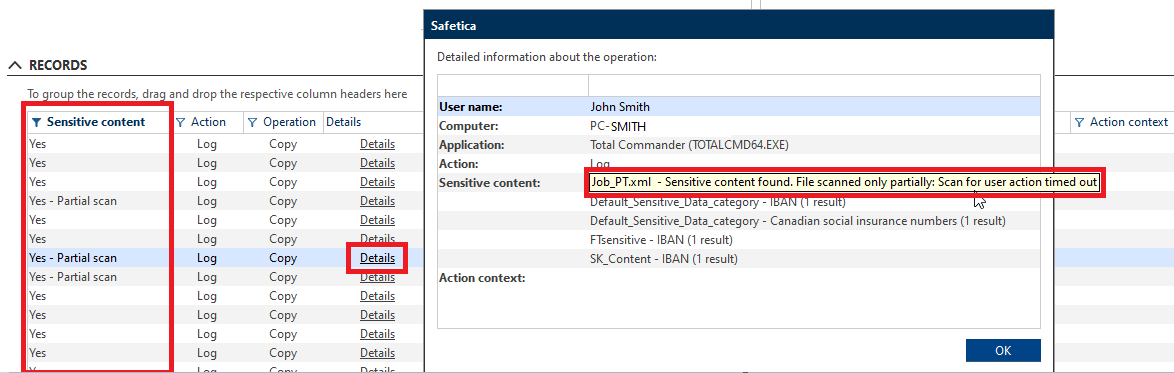
Results from our new sensitive content detection are visible in Safetica Management Console. Go to Protection > DLP logs > the Records table.
In the Sensitive content column, you will see:
- whether any sensitive data was found in a particular file
- whether the content detection finished completely or only a part of the file was analyzed
For now, if any of the time limits mentioned below are exceeded, sensitive content detection is stopped. If no problem is found in the analyzed part of the file, the action is allowed.
You will see the reason why a partial analysis did not finish after clicking the Details link in the Details column:
|
Partial scan reasons |
Description |
|
Scan timed out |
The maximum time reserved for searching sensitive data in a file was exceeded. |
|
Scan for user action timed out |
The time limit for sensitive content detection initialized by user actions is very short (a few seconds), so that users do not need to wait long for the results. If the analysis does not finish in time, a partial result with this message is returned. |
|
Text parsing timed out |
The time limit was exceeded even before any text was parsed. This can happen, for example, when trying to parse unsupported formats or in extremely busy endpoints, when the system prioritizes other tasks, so the detection does not even start. |