Information in this article applies to Safetica 10 or older.
Safetica 10 brings a new content inspection feature – the Optical character recognition (OCR) for detecting sensitive data in image-based files.
In this article, you will learn:
- How does OCR in Safetica 10 work?
- How to select OCR language?
- Where to configure OCR?
- How to select file types for OCR?
- How to activate or deactivate OCR for a specific endpoint?
- What does the admin see in logs?
- Use case
How does OCR in Safetica 10 work?
The OCR feature is disabled by default. This way, the admin can selectively control the load the OCR technology has on endpoints.
Our OCR supports the following image types: .png, .tiff, .jpg, .jpeg, .jpe, .bmp.
We can, however, extract images also from other file types, such as .pdf documents, presentation files, ebooks, etc. You can find the list of supported formats here.
Due to performance reasons, we only scan files that have at least 75% of pages covered by images. A “page covered by images” has images on at least 70% of its area.
OCR limitations
Safetica's OCR technology is primarily designed to extract sensitive content from scanned text documents. The scan quality is optimized to balance reasonable performance demands and the highest possible accuracy. Therefore, the technology may have difficulty processing certain types of text, such as:
- text blended with background
- low-quality images
- scattered words without a clear paragraph structure
- handwritten text
- and more.
As mentioned above, OCR is not bulletproof. We recommend testing its accuracy on sample documents and using it as a complement to other security measures. If you feel OCR does not work according to your expectations, please contact Safetica Support.
How to select OCR language?
OCR language settings can be found in Protection > Data categories > Optical character recognition language. The configuration is independent of Safetica Client language configured for endpoints. It is also centralized and unified for the whole environment (cannot be set differently for individual endpoints).
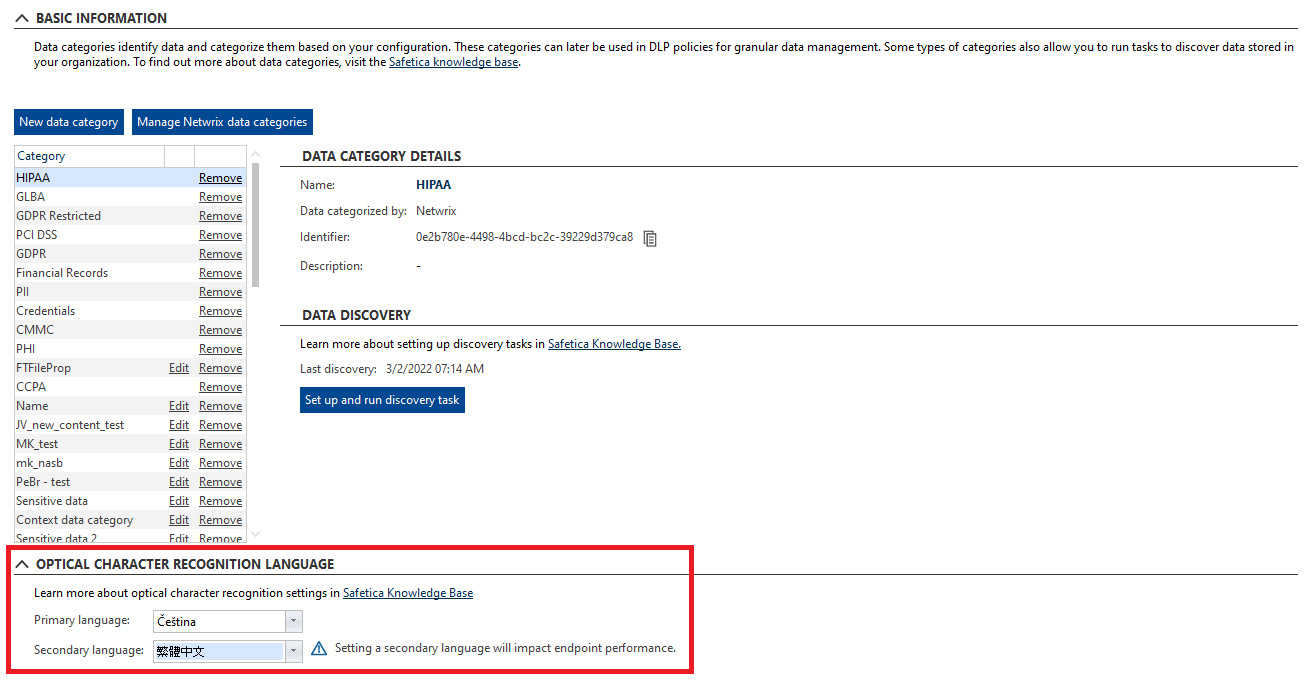
You can choose 2 different languages to be scanned by OCR, which may be useful for customers with multilingual environments. However, setting a secondary language will impact endpoint performance.
Setting a secondary language can improve detection accuracy in multilingual environments. It is useful mainly for different character sets, such as Cyrillic vs Latin vs Chinese alphabets.
Languages without special characters are a subset of languages with special characters. This means that if you set e.g. Czech or German as your primary language, then setting English as a secondary language is not necessary, since all the characters of English are already contained in Czech/German character sets.
Where to configure OCR?
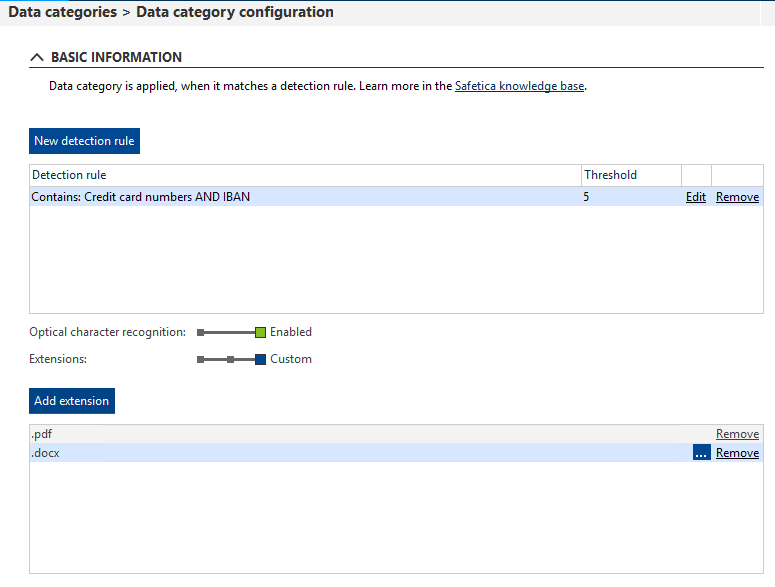
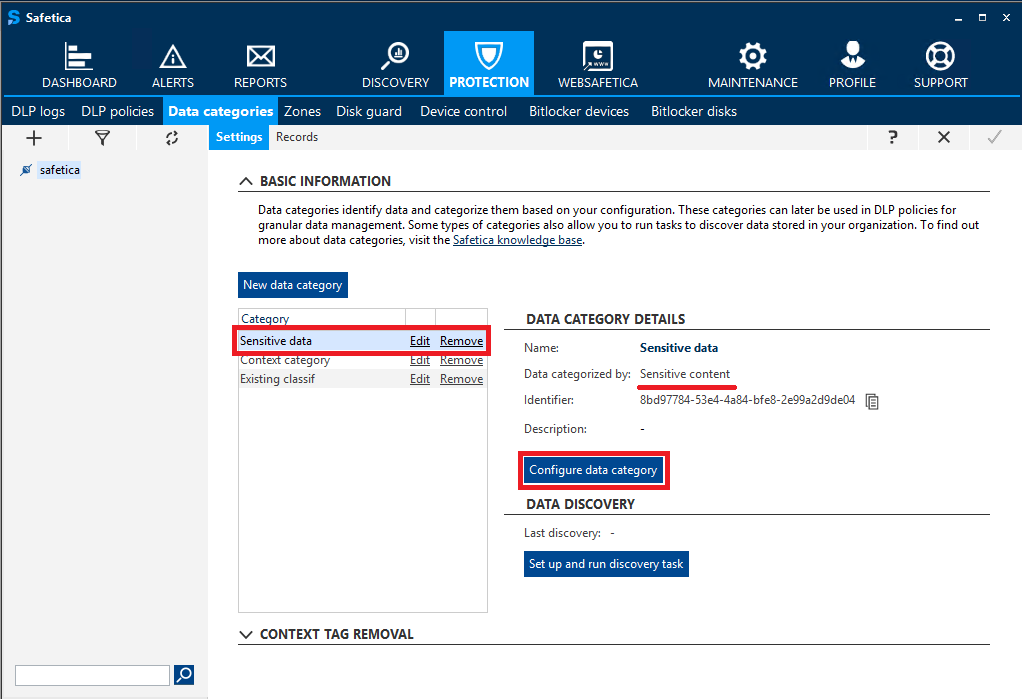
You can configure settings related to content inspection in Safetica Management Console > Protection > Data categories. Just select a sensitive content data category in the list on the left or create a new one, and click the Configure data category button.
When you enable OCR in one data category, it will be activated for all file types specified in that data category.
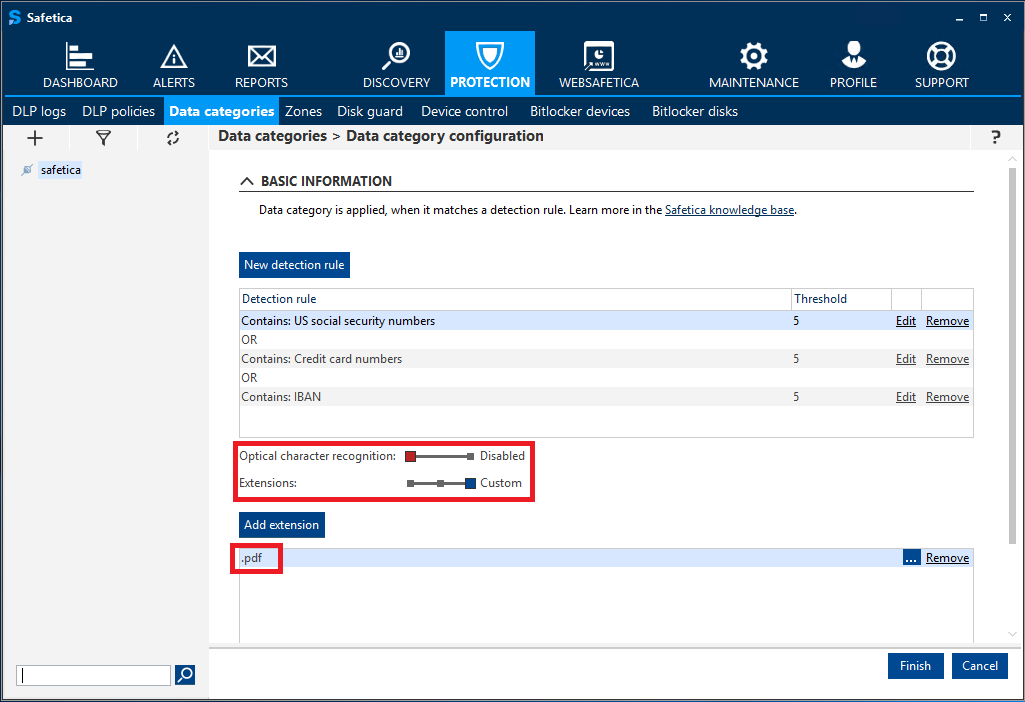
In the next step, you will see new options available under the detection rule configuration: Optical character recognition and Extensions. The sliders are independent of each other.
How to select file types for OCR?
When OCR is enabled, it is launched only for file types specified in the Extensions section, not for all files.
For example, if the admin enables OCR and then only sets the .pdf extension in the Extensions section, no other files, not even .jpeg or .bmp image files, will be scanned with OCR. If the admin selects Recommended in the Extensions section, OCR will only launch for the Recommended file types.
How to activate or deactivate OCR for a specific endpoint?
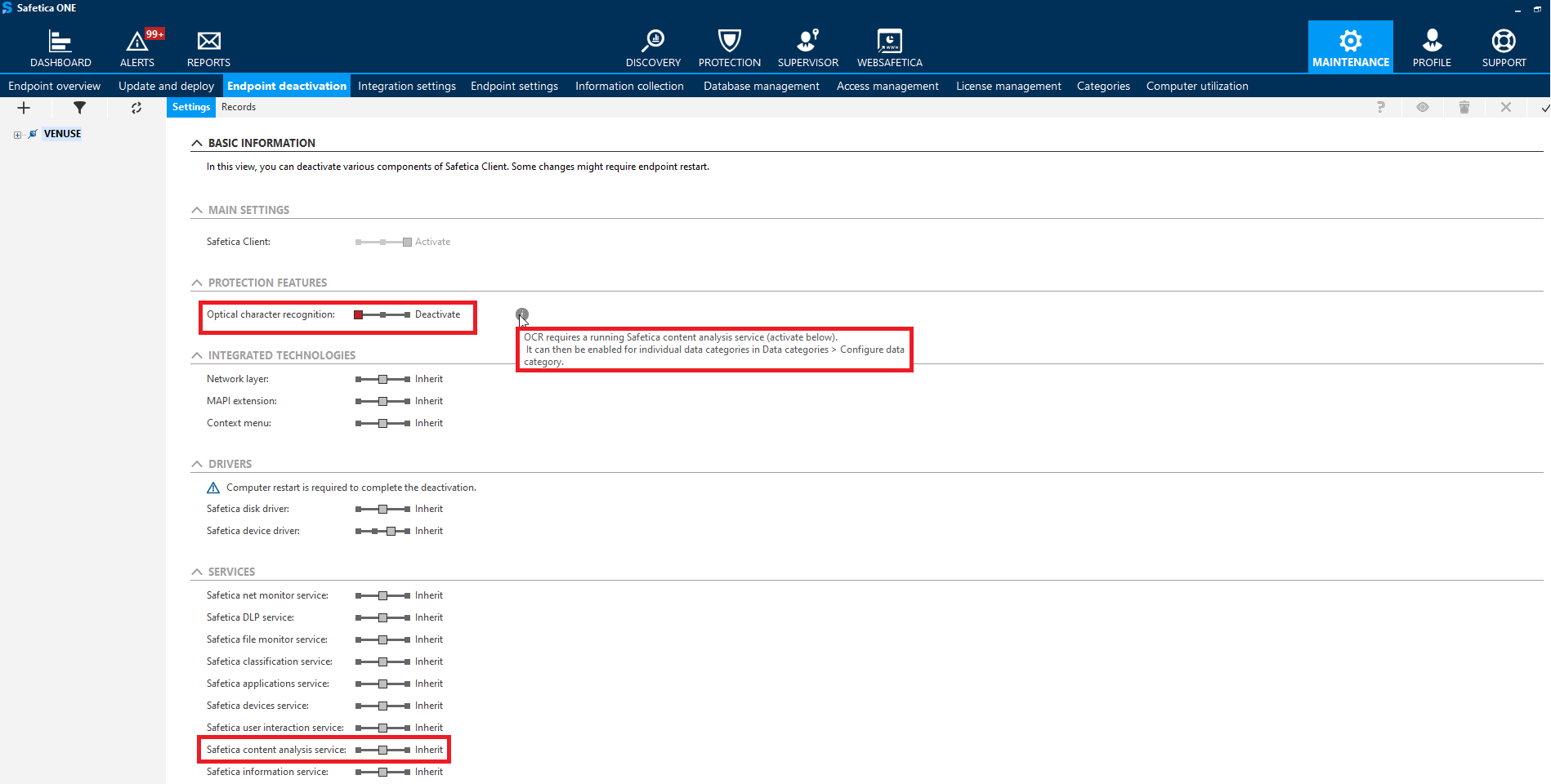
To activate or deactivate the OCR feature for a specific endpoint, go to Maintenance > Endpoint deactivation, select the endpoint or group in the user tree, and in the Protection features section select the desired option with the Optical character recognition slider.
OCR depends on content analysis service. If you deactivate content analysis service, OCR will not run, even if you activate it in the Protection features section.
What does the admin see in logs?
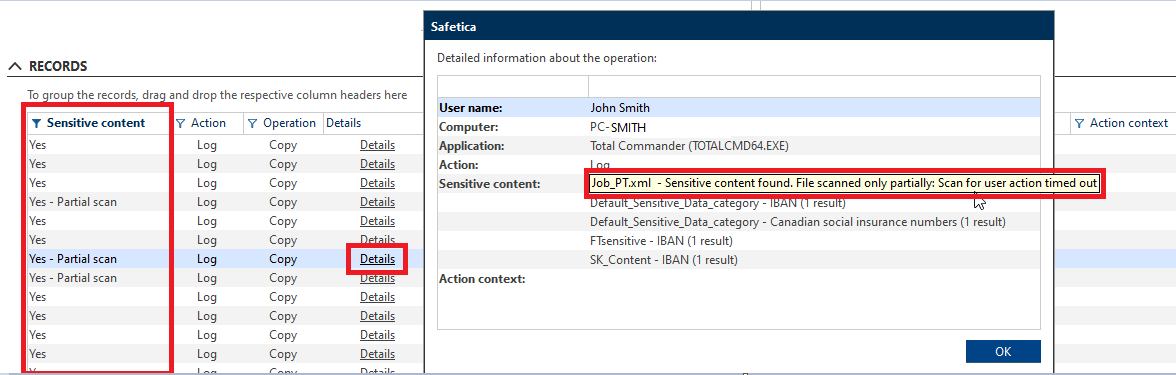
Results from our new content inspection are visible in Safetica Management Console. Just go to Protection > DLP logs and click Details in the Records table.
Use case
A company often uses .pdf, .docx, .pptx, .html, and .xml files. They know, however, that sensitive data (credit card numbers and IBANs) can only be found in .pdf and .docx files.
They create a data category that will OCR-scan only .pdf and .docx files and nothing else. This setting completely excludes image file types from OCR-scanning, so the company will not needlessly burden their users and endpoints.