If you wish to protect specific data in your company, you need to classify them first.
Data classifications allow you to define what data is considered sensitive in your company (e.g. personal information, credit card numbers, outputs of certain applications, etc.) and help you classify files into different groups based on who, where, and how can work with them. You can use data classifications in policies to detect and secure files that contain sensitive information.
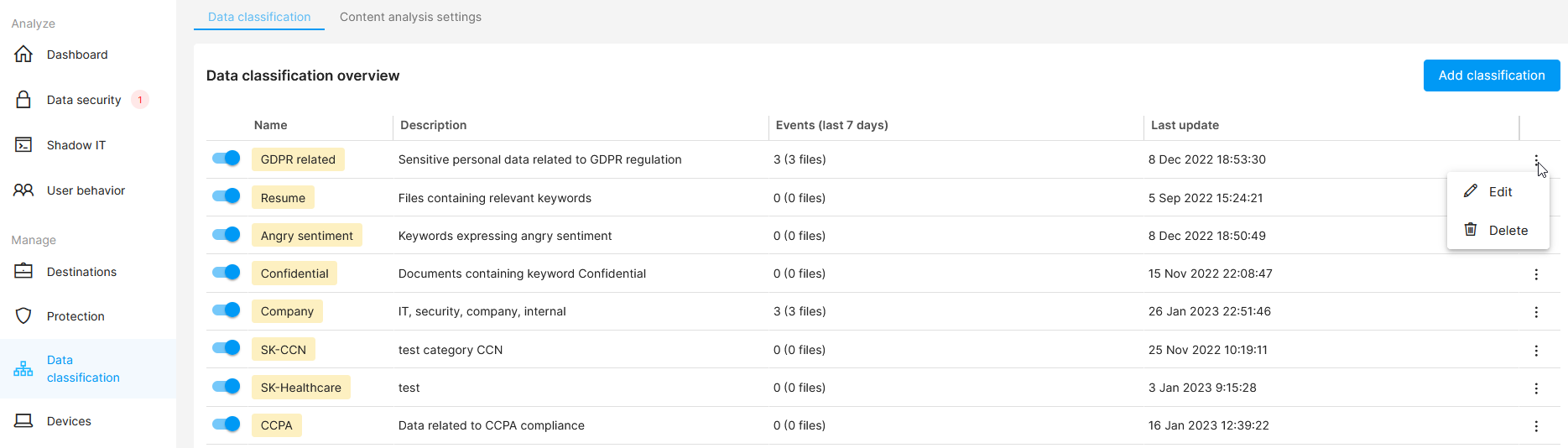
In the Data classification section, you can see a list of data classifications and when they were last edited.
Safetica NXT offers several pre-defined data classifications related to global data protection regulations, which may be used out-of-the-box. It also offers a large number of pre-defined classification rules which can be used to create your own custom data classifications.
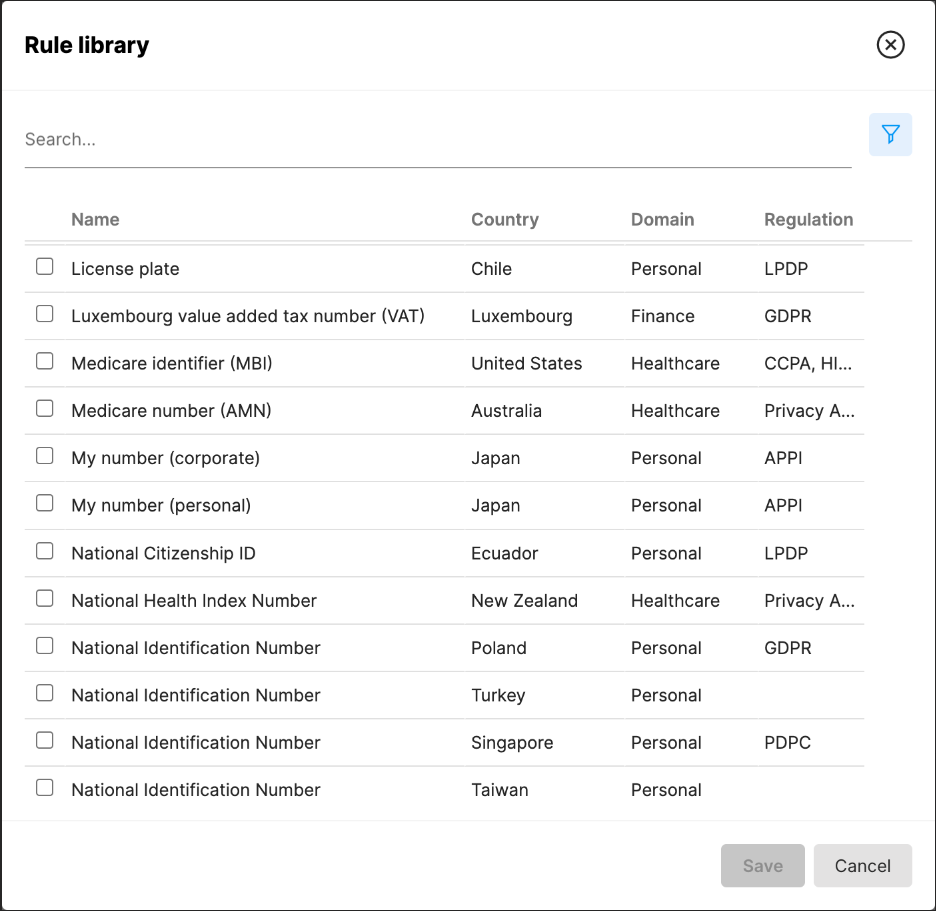
Data classifications are not prioritized. They are evaluated, and protection is determined by linked policies and their priority. New data classifications are always added to the bottom of the list.
You can also see the number of events matched by a particular data classification in the last 7 days, so that you know whether it works correctly. Click the number to see filtered matching events in Data security.
What file types does Safetica NXT analyze?
Safetica NXT analyzes only specific, best-practice file types:
txt, .xml, .html, .htm, .rtf, .zip, .csv, .pdf, .doc, .docx, .docm, .xls, .xlsx, .xlsm, .ppt, .pptx, .pptm, .pps, .ppsx, .ppsm, .msg, .eml, .one, .odt, .ods, .odp, .md, .epub
It is not possible to analyze content in encrypted or password-protected files. To protect such files, create a general policy focused on the desired file type (e.g. a policy that targets all .zip files).
How does OCR in Safetica NXT work?
Safetica analyzes the content in selected file types. With OCR, you can expand the scope to images, such as photos and scanned documents. The OCR feature is disabled by default. This way, the admin can selectively control the load the OCR technology has on devices.
Our OCR supports the following image types: .png, .tiff, .jpg, .jpeg, .jpe, .bmp.
We can, however, extract images also from other file types, such as .pdf documents, presentation files, ebooks, etc. You can find the list of supported formats here.
Due to performance reasons, we only scan files that have most pages covered by images.
Read next:
How to investigate files with sensitive content
How to create a new data classification