Information in this article applies to Safetica 10 or older.
A detection rule is a set of conditions which, when they are met, evaluate the data as sensitive.
In this article, you will learn more about:
- What pre-defined sensitive content algorithms and dictionaries are there in Safetica 10 or older
- Example of a detection rule
- When are AND/OR conditions used
- Detection range
- Detection threshold
- Custom expresions
- Custom dictionaries
- Backward compatibility
What pre-defined sensitive content content algorithms and dictionaries are there in Safetica 10 or older
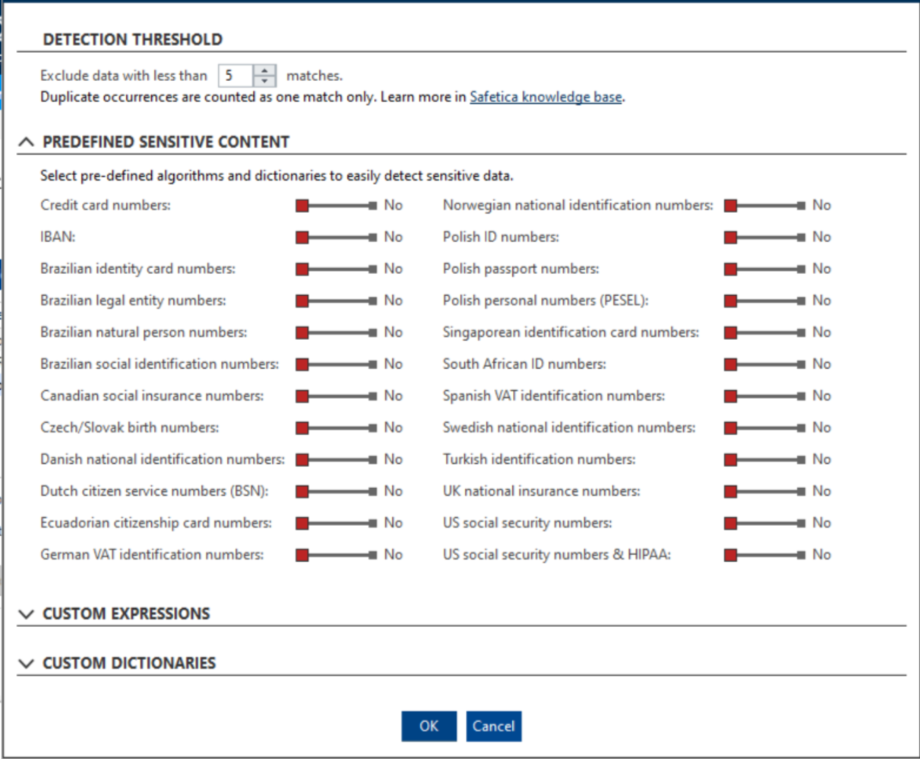
You can choose from many pre-defined sensitive content algorithms and dictionaries:
- Credit card numbers. Example: 4716-7750-2748-6285
- IBAN – the international bank account number format
- Brazilian identity card numbers
- Brazilian legal entity numbers
- Brazilian natural person numbers
- Brazilian social identification numbers
- Canadian social insurance numbers
- Czech/Slovak birth numbers – personal numbers of Czech or Slovak residents in standard format. Example: 925327/9508
- Danish national identification numbers
- Ecuadorian citizenship card numbers
- German VAT identification numbers
- Norwegian national identification numbers
- Polish ID numbers – Polish national ID card number
- Polish passport numbers
- Polish personal numbers (PESEL) – Polish national identification number
- Singaporean identification card numbers
- South African ID numbers
- Spanish VAT identification numbers
- Swedish national identification numbers
- Turkish identification numbers – Turkish national ID card number
- UK national insurance numbers – national insurance number of UK residents. Example: AA 12 24 56 C
- US social security numbers – social security numbers of US residents. This also includes the ITIN (Individual Taxpayer Identification Number). Example: 123 - 45 - 6789
- US social security numbers & HIPAA – the system searches for a combination of US social security numbers and data from HIPAA dictionaries. The dictionaries are regularly updated during definition updates and contain lists of companies, health conditions and drugs. HIPPA includes: HIPAA.companies, HIPAA.diseases, HIPAA.diseases-icd10, HIPAA.drugs
HIPAA (Health Insurance Portability and Accountability Act) is an act governing the handling of personal information about the health condition of patients in healthcare facilities in the US.
Detection rule example
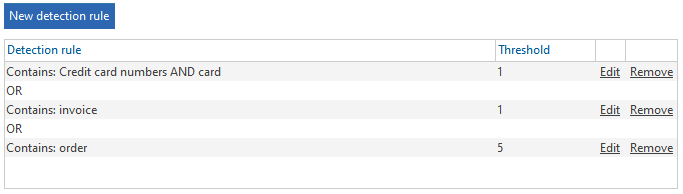
The example configuration could be used to detect financial documents.
Detection rule #1 is matched when a credit card number AND the word "card" are found in a document within a range of 1,800 characters. Detection rule #2 is matched when the word "invoice" is found. Detection rule #3 is matched when the word "order" if found at least 5 times.
If detection rule #1 OR detection rule #2 OR detection rule #3 are matched anywhere in the file, the document will be evaluated as sensitive.
When are AND/OR conditions used
If you specify several conditions within 1 detection rule, all of these must be matched. In other words, the relationship between conditions within 1 detection rule is "AND". For the example above, detection rule #1 is matched when both a credit card number AND the word "card" are found.
A detection rule is applied only when its conditions are met.

If you specify several detection rules within 1 data category, at least 1 of these must be matched. The relationship between several detection rules is "OR". For the example above, any of the three conditions must be matched to detect the configured data category.
Sensitive data is detected when at least one detection rule is applied.
Detection range
The detection range is in place to increase the accuracy of results and lower the number of false positive matches.
Detection range in practice means that "AND" rules must be matched within a range of 1,800 characters - roughly the amount of text which fits a single A4 page. This range is applied on a plain text version of files and does not consider actual document pages.
Detection threshold
The threshold specifies the minimum number of occurrences of the detection rule which must be reached to evaluate a file as sensitive. If a file contains fewer occurrences, it will not be classified as sensitive.
Duplicate occurrences are counted as one match only.
This means that if you have one keyword (e.g. the word "confidential") in a document multiple times, it is counted as one match.
Example 1: You create a rule with the pre-defined algorithm for credit card numbers and set the threshold to 5.
Files with 5 or more unique credit card numbers will hit the threshold and will be considered sensitive. Files with 5 or more identical credit card numbers will not be considered sensitive, because duplicate occurrences are counted as one match only.
Example 2: You create a rule with 10 keywords (e.g. “invoice”, “confidential”, “credit card”, ….) and set the threshold to 5.
To hit the threshold and be considered sensitive, a document must contain 5 or more different keywords. Files that contain 5 identical keywords will not be considered sensitive, because duplicate occurrences are counted as one match only.
Example 3: You create a rule combining the pre-defined algorithm for credit card numbers and a keyword (e.g. “confidential”) and set the threshold to 5.
Documents that contain the word “confidential” together with five different credit card numbers will hit the threshold and be considered sensitive.
Custom expressions
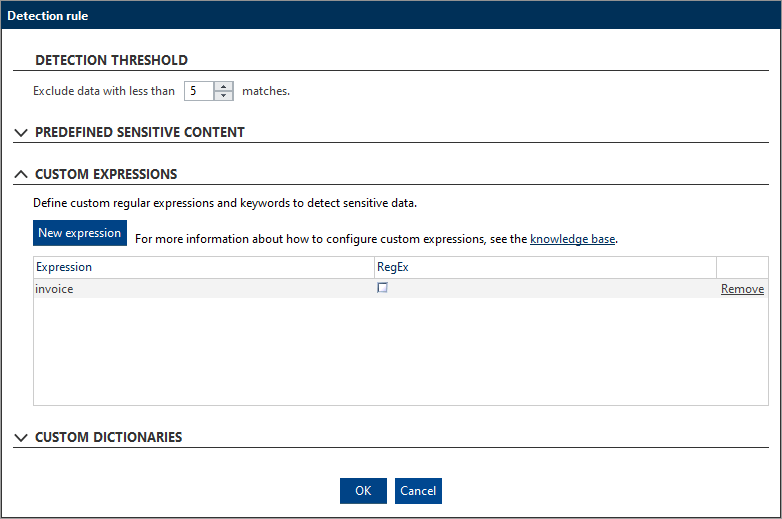 In this section, you can specify your own keywords and regular expressions for detecting sensitive data in files.
In this section, you can specify your own keywords and regular expressions for detecting sensitive data in files.
Keywords are not case-sensitive.
Regular expressions are evaluated based on ECMAScript syntax.
Custom dictionaries
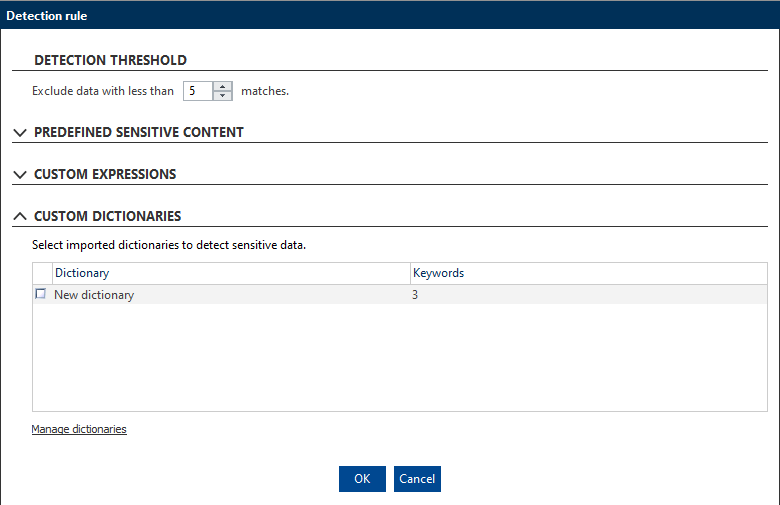
Here you can select dictionaries containing words to be detected as sensitive data. You can add a list of customer names or identifiers, project names, technical terms, or other keywords which often signify sensitive content (common words and phrases in contracts, personal CVs, etc.).
To import your own dictionary, create a text file with words that you want to detect as sensitive. Each word must always be placed on a new line.
To import, update, or remove a dictionary, click Manage dictionaries.
To preserve endpoint performance, certain limitations are imposed on using custom dictionaries:
- custom dictionaries can be imported as .TXT files encoded as UTF-8 with BOM
- the imported dictionaries can contain a combined total of up to 500,000 keywords
- up to 50 individual dictionaries can be imported
- dictionaries only support plain text keywords, regular expressions can be specified in a separate configuration section in Safetica Management Console
- keywords are delimited by line breaks, i.e. 1 line of the dictionary file = 1 keyword
Backward compatibility
After updating to Safetica 9.1, existing sensitive content configurations will be converted to the new system. Previously, sensitive data detection only used OR conditions, therefore, in order to maintain this logic, existing configurations will be converted into individual detection rules.
|
Version
|
Sensitive content configuration
|
|---|---|
| Safetica 9.0 or older | credit card numbers OR "card" OR "invoice" OR "order" |
| Safetica 9.1+ | Detection rule #1: credit card numbers Detection rule #2: "card" Detection rule #3: "invoice" |
The new detection rules are backward compatible with clients of older version to a certain degree:
- older endpoint clients will only recognize detection rules with a single condition
- older endpoint clients will apply the highest set value of threshold, in case various threshold settings are used for individual detection rules
For example:
|
|
Conditions
|
Threshold
|
|---|---|---|
| Detection rule #1 | credit card numbers AND "card" | 1 |
| Detection rule #2 | "invoice" | 1 |
| Detection rule #3 | "order" | 5 |
On older endpoint clients, detection rule #1 is ignored because it includes multiple conditions. Detection rules #2 and #3 are both applied with threshold at 5, since it is the highest set value. Consequently, this is the applied configuration:
|
Conditions
|
Threshold
|
|---|---|
| "invoice" OR "order" | 5 |