Product plans: Standard | Premium | Enterprise | On-Prem (see: Limits by plan)
Product differences:
-
Smart tags are not available in Safetica On-Prem and Safetica Platform Standard.
- User-applied tags are not available in Safetica Platform Standard.
Introduction
Data classification allows you to define what data is considered sensitive in your company. Learn more about data classification in general here.
✍️If you want to identify sensitive files by inspecting their content, you don’t need to create data classifications manually from scratch. To simplify and speed up the creation process, you can use data classification templates and predefined rules. Learn more here.
If you need to take context (e.g., where a file is stored, which app modified it, or from where it was downloaded), file types, or third-party classifications into account, you can do so by editing predefined rules or creating your own rules from scratch. Learn how to do that below.
In this article, you will learn:
- What are rules and elements
- How to create classification rules from scratch
- What elements can you use in your data classification
What are rules and elements
Rules and elements are two layers that define the scope of a data classification.
Example: A GDPR data classification consists of several rules related to personal data from various EU countries. Each rule consists of several elements that specify that rule, usually, these combine regexes and keywords.
|
Data classification |
Rule |
Element |
|
GDPR |
Austrian passport numbers |
[A-Za-z] ?\d{7} |
|
österreichisch reisepass, reisepass |
||
|
French driver’s license numbers |
\d{12} |
|
|
permis de conduire, drivers license |
||
|
Czech birth numbers |
\b[0-9]{2}(?:[0257][1-9]|[1368][0-2])(?:0[1-9]|[12][0-9]|3[01])/?[0-9]{3,4}\b |
|
|
Rodné číslo, identifikační číslo, osobní identifikační číslo, czech republic id |
||
|
German social security numbers |
[0-9]{2} ?[0-3][0-9][0-1][0-9][0-9]{2} ?[A-Z][0-9]{3} |
|
|
ausweis, identifizierungsnummer, personalausweis, sozialversicherungsausweis, sozialversicherungsnummer, versicherungsnummer |
✍️During policy evaluation, a classification is applied, if at least one of its rules is matched (OR relationship between rules). Also, all elements must be matched for the rule to be valid (AND relationship between elements).
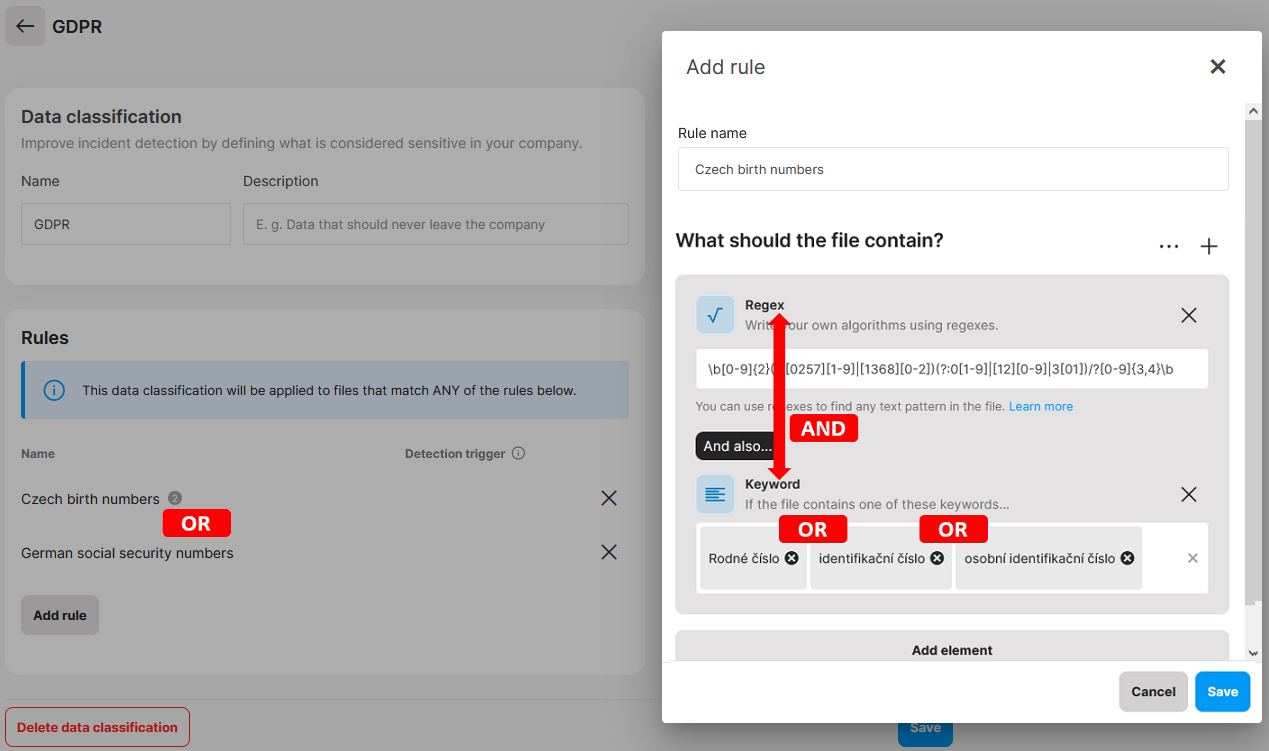
Example: A document contains Czech birth numbers and the term “rodné číslo”. Our previously-defined GDPR data classification will apply to this document, because one of its rules (Czech birth numbers) is matched. The rule is valid, because both elements contained in it were matched (the regex Czech birth numbers and the keyword “rodné číslo”).
How to create classification rules from scratch
- Go to the Data classification section and click Create new (or select an existing classification to edit it).

- Click Create new rule.

- Add your first element: You can add content-based elements, such as keywords, predefined algorithms, or regexes, and adjust their detection trigger. You can also add elements that detect context, file types, or a third-party classification. Learn more about individual elements of classification rules below.
- If needed, click Add element and add more elements you want to have in the rule.
- Name the rule and click Save.
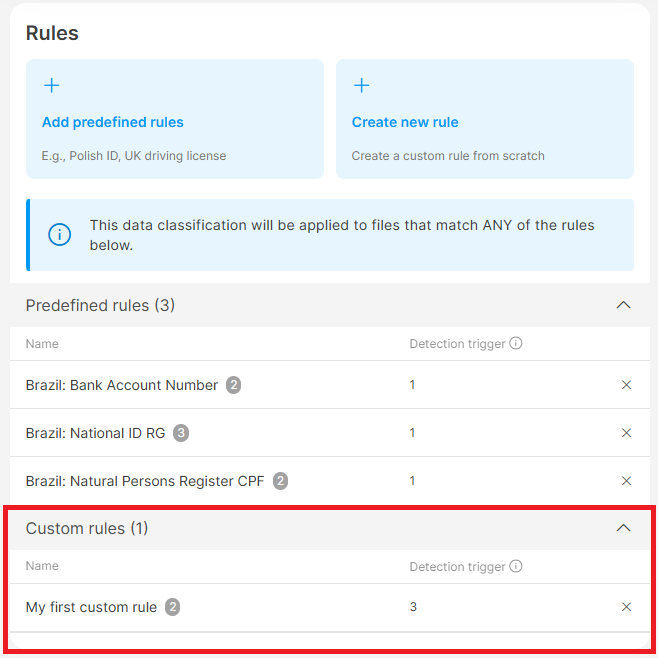
- Rules created from scratch will appear in the Custom rules section of your data classification. Learn more about the difference between Custom rules and Predefined rules here.

- You can add more rules or save the data classification.
What elements can you use in your data classification
Elements are divided into 4 sections, and you can combine them as needed:



1. Elements related to content analysis
If the file contains...
- Predefined algorithms, Keyword, Regex: You can specify what file content should be considered sensitive. Safetica utilizes three methods for sensitive content analysis - predefined algorithms (built-in healthcare, financial, and personal details algorithms), keywords, and regexes. I.e. you can define that a file is sensitive if it contains certain keywords, matches our predefined algorithms, or your own custom regular expressions.
✍️Keywords are not case sensitive.
- Encrypted or unreadable content: You can also identify and control files that are encrypted or unreadable and therefore, their content cannot be analyzed for sensitivity.
❗To detect and control encrypted or unreadable files, you must have at least one other content-focused classification rule configured and linked to a policy – a rule for unreadable content alone or a data classification that is not used in any policy is not enough.
Example 1: You can block the transfer of encrypted files to protect sensitive files from being sent out of the company.
Example 2: You can allow only encrypted files to be transferred to company USB devices to protect them in case the USB is lost.
✍️Dictionaries: You can copy and paste up to 10,000 keywords into one rule to serve as a custom dictionary. The keywords must be separated by line breaks.
Click  to set the detection trigger for the whole sensitive data section.
to set the detection trigger for the whole sensitive data section.
Click 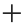 or the Add element button to add more elements to the rule.
or the Add element button to add more elements to the rule.
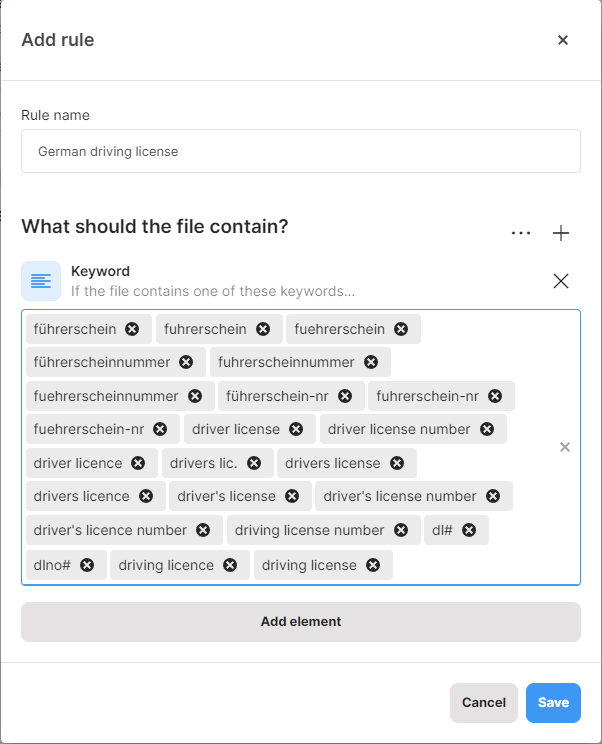
What is the detection trigger and how it works
You can narrow down the number of classified documents and avoid false positives by enabling the detection trigger. The detection trigger defines the minimum number of occurrences of sensitive data that must be found in a file for the data classification to apply. It only works for elements related to content analysis.
The detection trigger works on the rule level, so it applies to all combinations of keywords, regexes, predefined algorithms, and dictionaries that you choose for the rule.
Example: A company works with documents that contain a birth number on daily basis. It is unusual, however, for one document to contain several birth numbers. They set the detection trigger to 5 on the “Czech birth numbers” rule. This way, only files with 5 combinations of the birth number and the “rodné číslo” keyword will be classified with the GDPR data classification. Files with less than 5 matches will not be classified.
❗Duplicate occurrences are counted as one match only.
This means that if you have one keyword (e.g. the word "confidential") in a document multiple times, it is counted as one match.
Example 1: You create a rule with the pre-defined algorithm for credit card numbers and set the threshold to 5.
Files with 5 or more unique credit card numbers will hit the threshold and will be considered sensitive. Files with 5 or more identical credit card numbers will not be considered sensitive, because duplicate occurrences are counted as one match only.
Example 2: You create a rule with 10 keywords (e.g. “invoice”, “confidential”, “credit card”, ….) and set the threshold to 5.
To hit the threshold and be considered sensitive, a document must contain 5 or more different keywords. Files that contain 5 identical keywords will not be considered sensitive, because duplicate occurrences are counted as one match only.
Example 3: You create a rule combining the pre-defined algorithm for credit card numbers and a keyword (e.g. “confidential”) and set the threshold to 5.
Documents that contain the word “confidential” together with five different credit card numbers will hit the threshold and be considered sensitive.
2. Elements related to from where the file was transferred
If the file was ever transferred from...
You can specify through which places the file went - Safetica can classify files that were transferred from:
- an app category: Choose one or more categories from the drop-down list. Any file that is exported from the selected application category will be classified.
- a file path: Enter one or more local or network file paths. All files that are currently stored in these paths will be classified. Also, if at any time when the classification is in place, a protected user creates/copies a file to the selected file paths, it will be classified too. Files carry the classification even when they later move to different locations.
✍️🪟Win only: Safetica understands DFS (Distributed File System) shortcuts to shared folders. When you allow or block a server or shared folder, the same policy also applies to any DFS shortcuts that lead to it. In the records, you will always see the full, real path, even if users work with shortcuts.
- a website: Enter one or more web addresses; any file downloaded from the website will be classified.
❗Classification based on a file's origin works only for files that contain at least 6 bytes of data. For empty or very small files (containing less than 6 bytes of data), it may behave inconsistently across applications.
You can define e.g. that a file is sensitive if it comes from a CRM system OR accounting software AND is also stored in a particular location.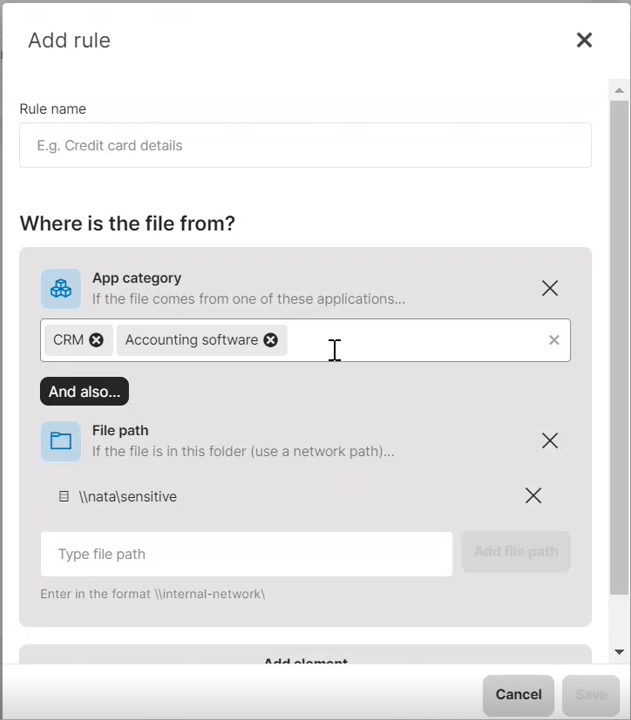
3. Elements related to file properties
If the file attribute is...
- File type: Classify files by their type to add more granularity to data classification. This is often combined with other criteria to restrict (or allow) only selected file types. In File type, you can choose a single file extension (e.g. pdf) or a whole category (e.g. 3D image):
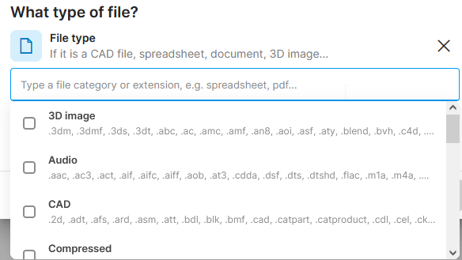
✍️ Learn which specific file extensions are there in individual file type categories here.
-
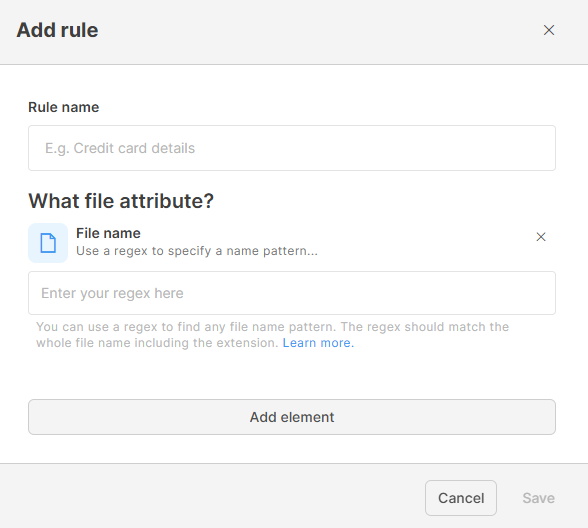
File name: Classify files by their naming pattern. This is useful when your company uses standard names for sensitive files and you want to catch files whose names don’t match their actual sensitivity. In File name, you can use a regex to match complete file names, including extensions.

4. Elements related to already existing 3rd-party data classification
If the file is already classified...
If you already use a 3rd party data classification tool, you can define that files classified by this tool are sensitive. Safetica is universally compatible with third-party classification tools that store classification information (tag) in file properties. We have specifically confirmed compatibility with the following classification tools:
- Netwrix
- Microsoft Purview Information Protection
- Boldon James
- Tukan GREENmod
❗Limitation: Safetica cannot read existing classification from OpenOffice files (such as *.odt, *.ods, or *.odp files).
What are classification identifiers
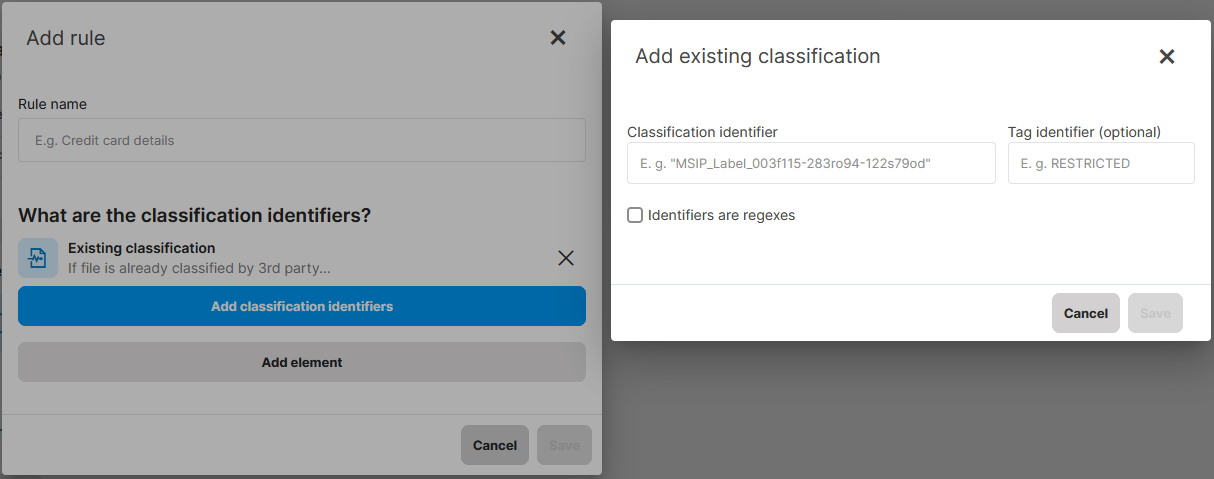
- Classification identifier specifies the classification type in general and is required.
- Tag identifier specifies the classification’s more specific parameter and is optional.
- The Identifiers are regexes checkbox is an optional setting for cases when you want to evaluate the identifiers not as specific strings but as regexes. It allows you to search for regular expressions instead of specific strings.
You can specify both the Classification identifier and the Tag identifier or leave one of them empty for a more general search.
✍️You can obtain the identifiers either from sample classified documents or from Azure Information Protection.
Examples of various identifiers:
|
Third-party technology |
Classification identifier |
Tag identifier |
|
Microsoft MIP sensitivity labels |
0034f115-2835-4348-b421-de66a63e347f |
|
|
Boldon James |
DLPTRIGGER |
[*{Internal}*] |
|
Tukan GREENmod |
TukanITGREENmodCATEGORY |
RESTRICTED |
For MIP sensitivity labels, the Tag identifier may be left empty.
How to obtain classification identifier from sample documents
If you have access to sample classified documents from your company, you can use them to find the classification identifiers:
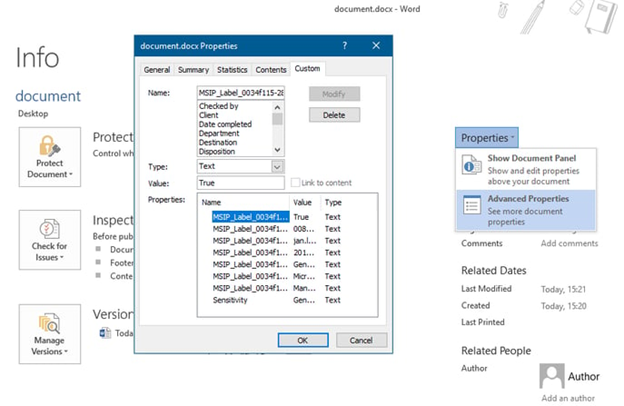
- Open the document(s) in Office suite.
- Click File > Info > Properties > Advanced properties.
- Under the Custom tab, you will find various properties.
- Identify the one that is common for your classified files. Then simply copy its name (or a part of it) into the Classification identifier field. Optionally, copy its “value” into the Tag identifier field.
How to obtain classification identifier from Azure Information Protection
If you’re using Azure Information Protection classification, you can easily obtain the required information from the Microsoft Entra admin center.
- In the admin center, go to the Azure Information Protection section.
- There, in the Policies section, you will find all existing policies:
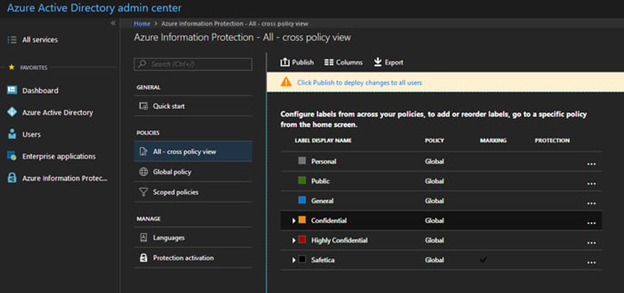
3. Choose the policy you need detected by Safetica and open it. On the very bottom of the configuration window, you will find your Label ID:
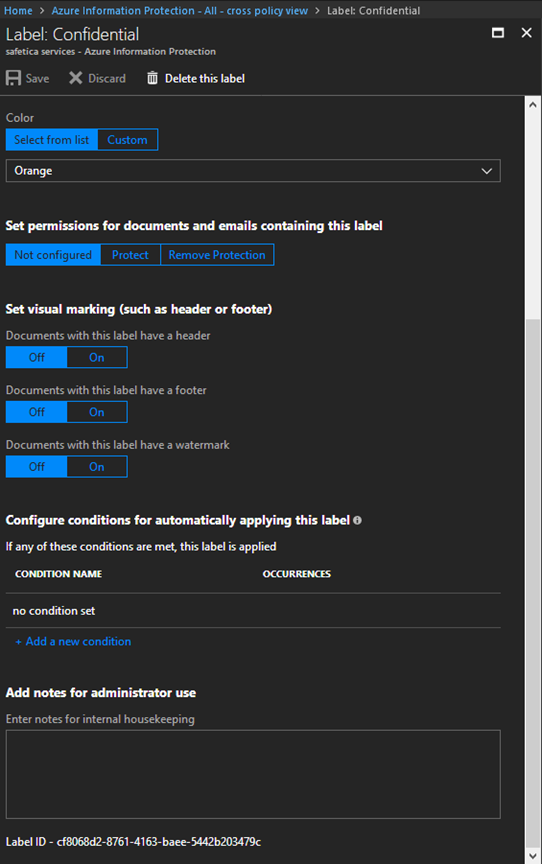
4. For Safetica to register your files labeled with Microsoft MIP sensitivity labels, you need to enter into the Classification identifier field one of the following:
- MSIP_Label_ - if you enter this string, Safetica will detect all files classified by MIP, regardless of label ID.
- The specific label ID - e.g. cf8068d2-8761-4163-baee-5442b203479c - Safetica will detect files classified by MIP as “Confidential” (as per the example above).
For MIP sensitivity labels, the tag identifier may be left empty.
5. Tags
If the file has tags...
- ✨Safetica Platform only: Smart tags: Smart tags help you discover sensitive files automatically with the help of AI, so you don’t have to create every classification rule manually. Learn more here.
- User-applied tags: User-applied tags let end users classify files manually with tags that admins create and manage in the Safetica console. By applying, changing, or removing a tag, users can influence how Safetica protects files. Learn more here.
FAQ
Q: I have a classification rule set up encrypted / unreadable files. But it does not work, the rule does not detect anything. Why?
A: To detect encrypted / unreadable files correctly, you must have at least one other content-focused classification rule set up and linked to a policy. Otherwise, content analysis will not run encrypted / unreadable files will not be detected.
Q: What specific file extensions are there in individual file type categories?
A: For the File type element, you can choose either a single file extension (e.g. pdf) or a whole category (e.g. 3D image). Individual file type categories contain the following extensions:
| File type category | File extensions |
| 3D image | .3dm, .3dmf, .3ds, .3dt, .abc, .ac, .amc, .amf, .an8, .aoi, .asf, .aty, .blend, .bvh, .c4d, .cag, .cal3d, .ccp4, .cfl, .cob, .core3d, .cshp, .ctm, .dff, .dpm, .egg, .fac, .fact, .fbx, .fes, .geo, .glm, .iv, .jas, .lwo, .lws, .lxo, .m, .ma, .max, .mb, .md2, .md3, .mdx, .mesh, .mm3d, .mmp, .mpo, .mrc, .nif, .obj, .off, .ogex, .ply, .pov, .prc, .rib, .rwx, .scn, .shp, .sia, .sib, .slp, .smd, .step, .stl, .stp, .tcp, .tri, .u3d, .vet, .vis, .vue, .w3d, .wings, .wrl, .x, .x3d, .xaml, .xgl, .xsi, .z3d |
| Audio | .aac, .ac3, .act, .aif, .aifc, .aiff, .aob, .at3, .cdda, .dsf, .dts, .dtshd, .flac, .m1a, .m4a, .m4p, .mka, .mp1, .mp2, .mp3, .mpa, .mpga, .mpu, .oga, .ogg, .smf, .sng, .wav, .wave, .wma |
| CAD | .2d, .adt, .afs, .ard, .asm, .att, .bdl, .blk, .bmf, .cad, .catpart, .catproduct, .cdl, .cel, .ckd, .cmp, .cpa, .dae, .dc, .dcd, .des, .dft, .dgk, .dgn, .dlv, .drwdot, .dst, .dwfx, .dwg, .dws, .dwt, .dxb, .dxe, .dxf, .dxx, .easm, .edrw, .fcw, .g, .gbx, .iam, .idw, .igs, .ipn, .ipt, .jt, .lcf, .lin, .mc9, .mcx, .model, .nc, .neu, .pla, .pln, .prt, .psm, .pwd, .pwt, .rfa, .rft, .rte, .rvt, .sab, .sat, .shx, .skb, .skp, .sldasm, .slddrw, .sldprt, .spt, .style, .t3001, .tcd, .tct, .tcw, .tcx, .unt, .vnd, .vtf, .vwx, .x_b, .x_t, .xv3 |
| Compressed | .7z, .ace, .arj, .bz, .bz2, .bzip, .bzip2, .car, .gz, .gzi, .gzip, .ice, .rar, .sfx, .tar, .tar.gz, .taz, .zip |
| Disk Image | .ccd, .cso, .cue, .daa, .dsk, .ima, .img, .imz, .iso, .isz, .md0, .md1, .mdf, .mds, .nrg, .omg, .swm, .tc, .tib, .udf, .vcd, .vdi, .vhd, .vmdk |
| E-book | .aeh, .azw, .azw3, .epub, .fb2, .ibooks, .lit, .lrf, .mbp, .mobi, .opf |
| Executable | .bat, .cmd, .exe, .jar, .jse, .jsx, .vbe, .vbs, .vbscript |
| Image |
.abm, .afx, .agif, .ai, .ais, .apm, .apng, .art, .awd, .bmc, .bmp, .cal, .cals, .can, .cdc, .cdr, .cdx, .cgm, .cil, .cin, .cmx, .cpc, .cpt, .cpx, .cr2, .crw, .csf, .ct, .cvi, .cvx, .dcm, .dcr, .dcs, .dds, .design, .dib, .djv, .djvu, .dng, .dpp, .dpx, .drw, .dt2, .dx, .ecw, .emf, .emz, .eps, .epsf, .erf, .exr, .fax, .fif, .fig, .fpx, .fs, .fxg, .gbr, .gif, .gih, .hdp, .hdr, .ica, .icn, .icon, .ilbm, .imj, .info, .int, .itc2, .ithmb, .ivr, .j, .j2c, .j2k, .jb2, .jbig, .jbr, .jfi, .jfif, .jif, .jiff, .jng, .jp2, .jpc, .jpe, .jpeg, .jpf, .jpg, .jpx, .jtf, .jxr, .kdc, .kdk, .lbm, .mat, .mbm, .met, .mgcb, .mgs, .mic, .mip, .mix, .mng, .mnr, .mos, .mpf, .mrb, .mrw, .nap, .ncd, .nef, .nrw, .odi, .omf, .orf, .oti, .pbm, .pcd, .pcx, .pd, .pdd, .pdn, .pef, .pfr, .pgm, .pict, .plt, .pm3, .pmg, .png, .pnm, .pp4, .pp5, .ppf, .ppm, .ps, .psb, .psd, .psid, .psp, .pspimage, .ptx, .px, .qif, .qti, .qtif, .raf, .ras, .raw, .rif, .riff, .s2mv, .sct, .sgi, .sld, .spp, .srf, .ste, .sun, .svg, .svgz, .tex, .tga, .thm, .tif, .tiff, .vml, .vsd, .vss, .vst, .wbmp, .wdp, .wmf, .wmp, .wpg, .x3f, .xar, .xbm, .xcf |
| Presentation | .pdf, .pot, .potm, .potx, .pps, .ppsx, .ppt, .pptm, .pptx |
| Spreadsheet | .csv, .prn, .xla, .xlm, .xls, .xlsb, .xlsm, .xlsx, .xlt, .xltm, .xltx, .xlw, .xps |
| Text | .doc, .docb, .docm, .docx, .dot, .dotm, .dotx, .odc, .odf, .odg, .odm, .odp, .ods, .odt, .otc, .otf, .otg, .otp, .ots, .ott, .rtf, .txt, .vcf, .wpd |
| Video | .avi, .bsf, .divx, .dvx, .flc, .flh, .fli, .flv, .flx, .gvi, .hdmov, .m15, .m1pg, .m1v, .m21, .m2a, .m2p, .m2t, .m2ts, .m2v, .m4e, .m4u, .m4v, .m75, .mj2, .mjp, .mjpg, .mkv, .mod, .moov, .mov, .movie, .mp21, .mp2v, .mp4, .mp4v, .mpe, .mpeg, .mpeg4, .mpg, .mpg2, .mpv, .mpv2, .mqv, .ogm, .ogv, .ogx, .qt, .qtm, .rm, .rv, .swf, .vob, .webm, .wm, .wmv, .xvid |
| Web | .css, .dhtml, .dochtml, .docmhtml, .dothtml, .htm, .html, .js, .mht, .mhtm, .mhtml, .php, .ppthtml, .pptmhtml, .shtm, .shtml, .xhtm, .xhtml, .xml |
| Windows | .adml, .admx, .alx, .ani, .ann, .aos, .aux, .b3d, .bak, .bin, .bio, .block, .bmk, .cab, .cat, .chm, .clb, .cnf, .cnt, .cpi, .cpl, .cur, .dat, .desklink, .dev, .dll, .dlx, .dmp, .drv, .dss, .dvd, .dxt, .dyc, .evtx, .ffa, .ffl, .ffo, .ffx, .fnt, .fon, .ftg, .fts, .gpd, .grl, .grp, .h1s, .hdmp, .hhc, .hhk, .hlp, .hpj, .htt, .icc, .icl, .icm, .ico, .idx, .inf, .ini, .ins, .ion, .its, .job, .kbd, .lnk, .log1, .log2, .manifest, .mapimail, .mdmp, .mfl, .mi4, .mlc, .mobileconfig, .mof, .msc, .msp, .msstyle, .msstyles, .mui, .mum, .mydocs, .nlp, .nls, .nt, .oem, .p7b, .pdr, .pfx, .pid, .pk2, .pol, .ppd, .prf, .pwl, .rco, .reg, .rfw, .rmt, .ruf, .scf, .scr, .sdb, .sfcache, .sqm, .swp, .sys, .theme, .tmp, .ttf, .vga, .vgd, .vim, .vxd, .wdf, .wer, .wpx, .xpm, .xrm-ms, .xwd |